 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerated Structure-Aware Reinforcement Learning for Delay-Sensitive Energy Harvesting Wireless Sensors
Paper and Code
Jul 22, 2018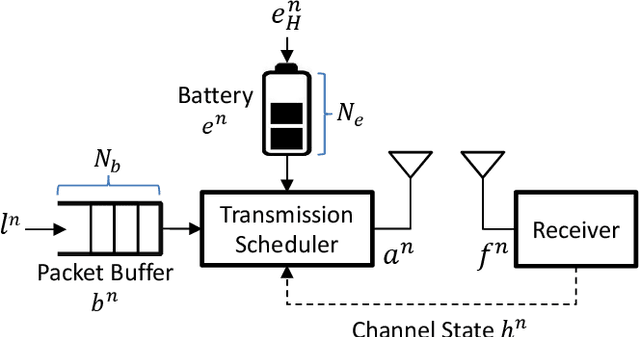
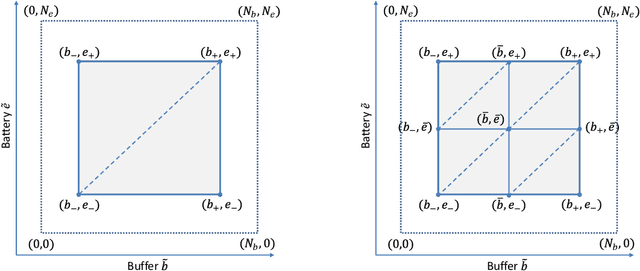
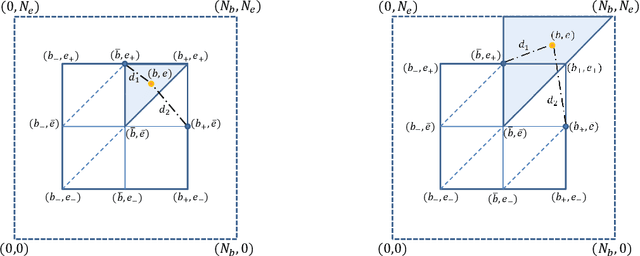
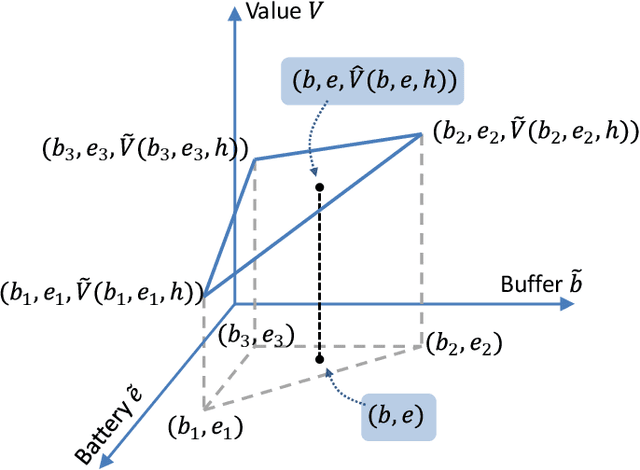
We investigate an energy-harvesting wireless sensor transmitting latency-sensitive data over a fading channel. The sensor injects captured data packets into its transmission queue and relies on ambient energy harvested from the environment to transmit them. We aim to find the optimal scheduling policy that decides whether or not to transmit the queue's head-of-line packet at each transmission opportunity such that the expected packet queuing delay is minimized given the available harvested energy. No prior knowledge of the stochastic processes that govern the channel, captured data, or harvested energy dynamics are assumed, thereby necessitating the use of online learning to optimize the scheduling policy. We formulate this scheduling problem as a Markov decision process (MDP) and analyze the structural properties of its optimal value function. In particular, we show that it is non-decreasing and has increasing differences in the queue backlog and that it is non-increasing and has increasing differences in the battery state. We exploit this structure to formulate a novel accelerated reinforcement learning (RL) algorithm to solve the scheduling problem online at a much faster learning rate, while limiting the induced computational complexity. Our experiments demonstrate that the proposed algorithm closely approximates the performance of an optimal offline solution that requires a priori knowledge of the channel, captured data, and harvested energy dynamics. Simultaneously, by leveraging the value function's structure, our approach achieves competitive performance relative to a state-of-the-art RL algorithm, at potentially orders of magnitude lower complexity. Finally, considerable performance gains are demonstrated over the well-known Q-learning algorithm.