Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAblation study of self-supervised learning for image classification
Paper and Code

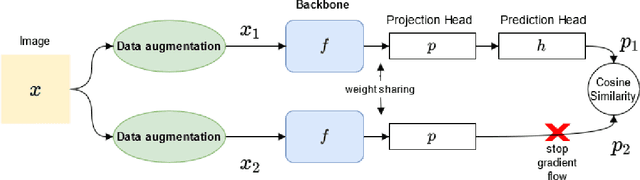
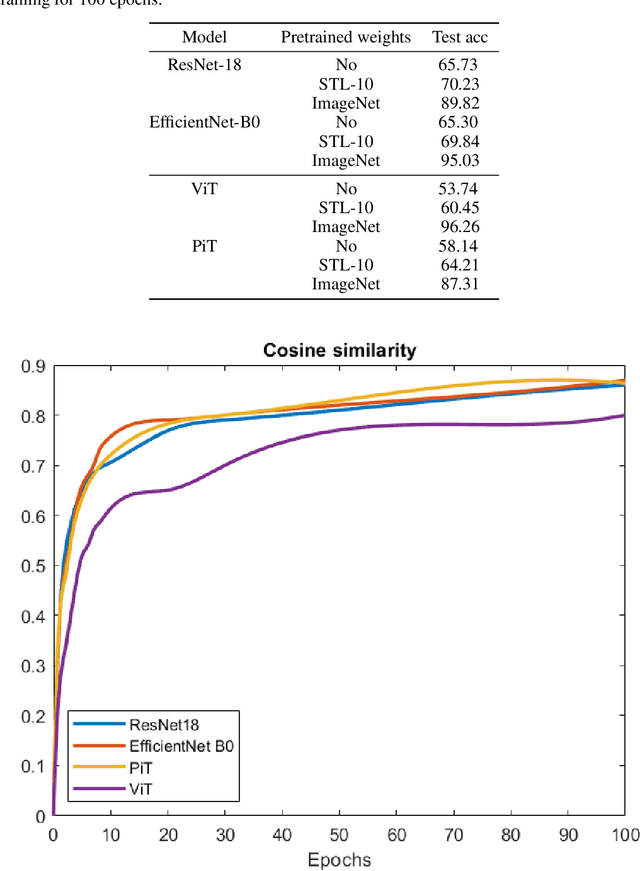
This project focuses on the self-supervised training of convolutional neural networks (CNNs) and transformer networks for the task of image recognition. A simple siamese network with different backbones is used in order to maximize the similarity of two augmented transformed images from the same source image. In this way, the backbone is able to learn visual information without supervision. Finally, the method is evaluated on three image recognition datasets.
View paper on