Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tidy Data Model for Natural Language Processing using cleanNLP
Paper and Code

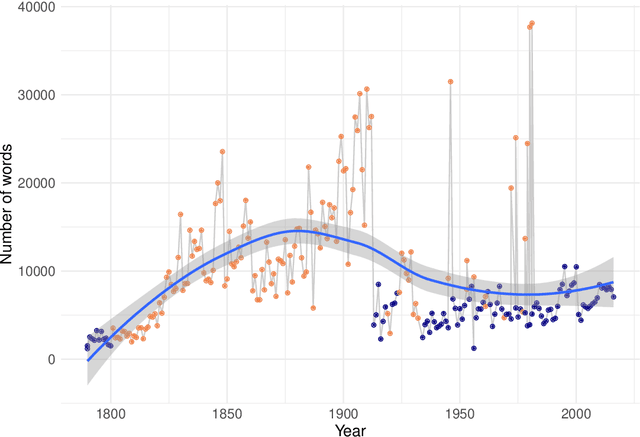

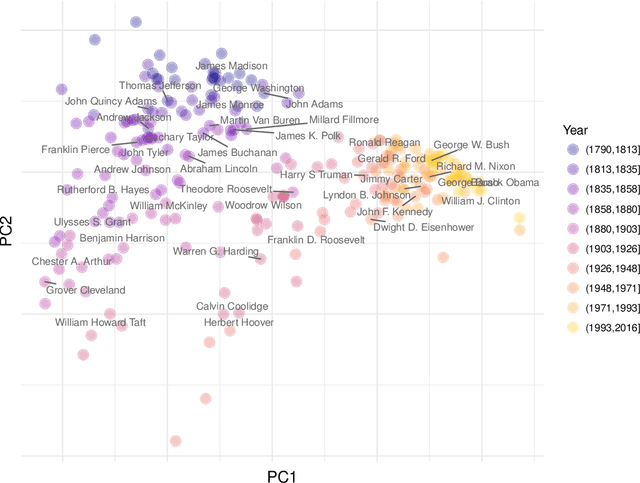
The package cleanNLP provides a set of fast tools for converting a textual corpus into a set of normalized tables. The underlying natural language processing pipeline utilizes Stanford's CoreNLP library, exposing a number of annotation tasks for text written in English, French, German, and Spanish. Annotators include tokenization, part of speech tagging, named entity recognition, entity linking, sentiment analysis, dependency parsing, coreference resolution, and information extraction.
* The R Journal, 9.2, 248-267 (2017) * 20 pages; 4 figures
View paper on