 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review of Data-to-Text NLG
Paper and Code
Feb 27, 2024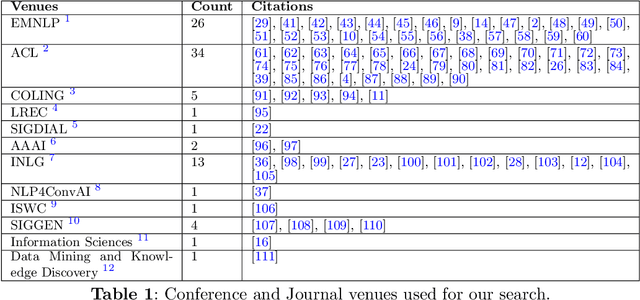
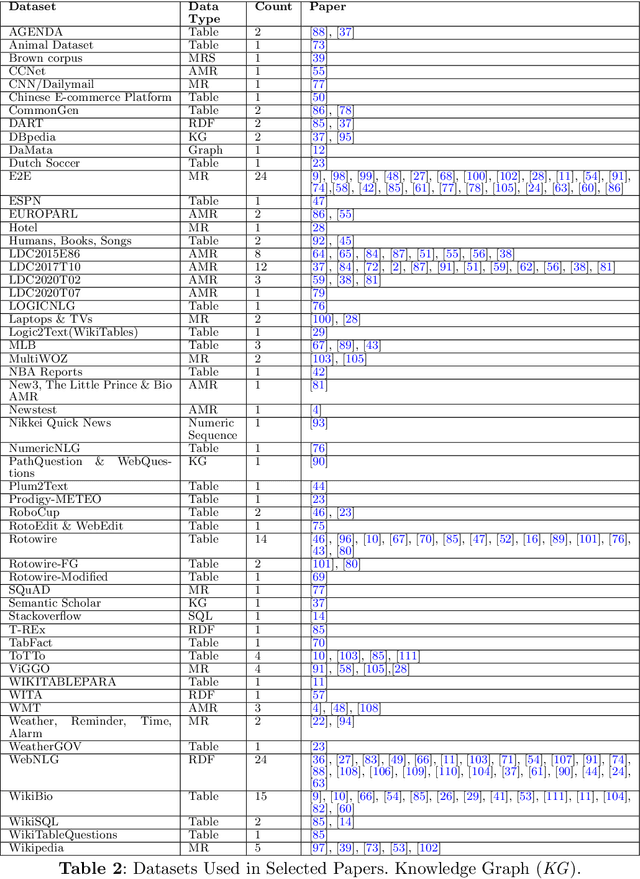
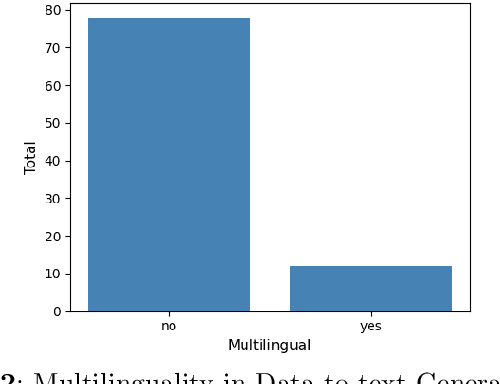
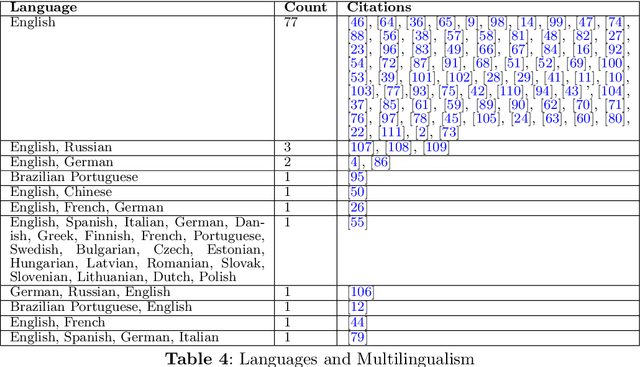
This systematic review undertakes a comprehensive analysis of current research on data-to-text generation, identifying gaps, challenges, and future directions within the field. Relevant literature in this field on datasets, evaluation metrics, application areas, multilingualism, language models, and hallucination mitigation methods is reviewed. Various methods for producing high-quality text are explored, addressing the challenge of hallucinations in data-to-text generation. These methods include re-ranking, traditional and neural pipeline architecture, planning architectures, data cleaning, controlled generation, and modification of models and training techniques. Their effectiveness and limitations are assessed, highlighting the need for universally applicable strategies to mitigate hallucinations. The review also examines the usage, popularity, and impact of datasets, alongside evaluation metrics, with an emphasis on both automatic and human assessment. Additionally, the evolution of data-to-text models, particularly the widespread adoption of transformer models, is discussed. Despite advancements in text quality, the review emphasizes the importance of research in low-resourced languages and the engineering of datasets in these languages to promote inclusivity. Finally, several application domains of data-to-text are highlighted, emphasizing their relevance in such domains. Overall, this review serves as a guiding framework for fostering innovation and advancing data-to-text generation.