 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Analysis of Morphological Content in BERT Models for Multiple Languages
Paper and Code
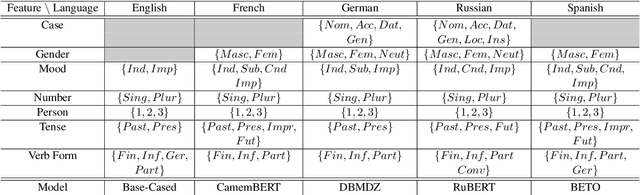
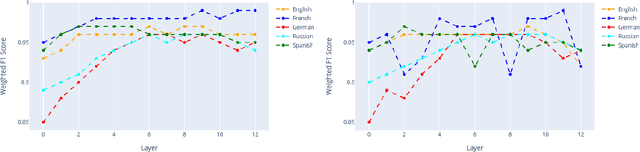

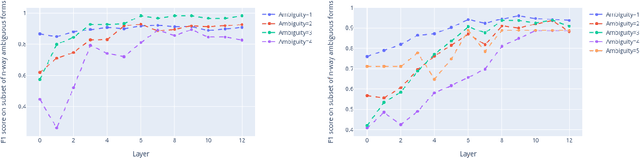
This work describes experiments which probe the hidden representations of several BERT-style models for morphological content. The goal is to examine the extent to which discrete linguistic structure, in the form of morphological features and feature values, presents itself in the vector representations and attention distributions of pre-trained language models for five European languages. The experiments contained herein show that (i) Transformer architectures largely partition their embedding space into convex sub-regions highly correlated with morphological feature value, (ii) the contextualized nature of transformer embeddings allows models to distinguish ambiguous morphological forms in many, but not all cases, and (iii) very specific attention head/layer combinations appear to hone in on subject-verb agreement.