 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Techniques for Identifying and Resolving Representation Bias in Data
Paper and Code
Mar 22, 2022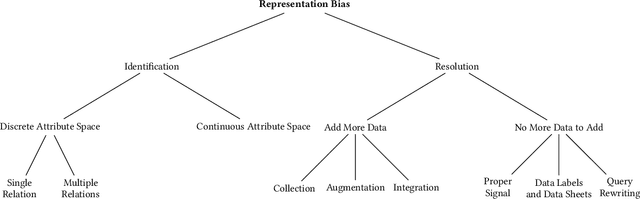
The grand goal of data-driven decision-making is to help humans make decisions, not only easily and at scale but also wisely, accurately, and just. However, data-driven algorithms are only as good as the data they work with, while data sets, especially social data, often miss representing minorities. Representation Bias in data can happen due to various reasons ranging from historical discrimination to selection and sampling biases in the data acquisition and preparation methods. One cannot expect AI-based societal solutions to have equitable outcomes without addressing the representation bias. This paper surveys the existing literature on representation bias in the data. It presents a taxonomy to categorize the studied techniques based on multiple design dimensions and provide a side-by-side comparison of their properties. There is still a long way to fully address representation bias issues in data. The authors hope that this survey motivates researchers to approach these challenges in the future by observing existing work within their respective domains.