 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Spectral Approach to Off-Policy Evaluation for POMDPs
Paper and Code
Sep 22, 2021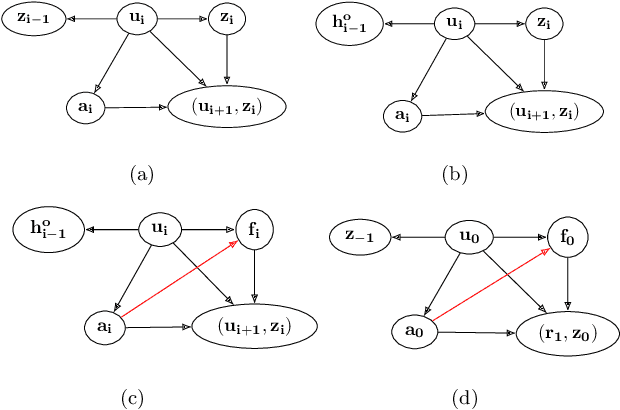
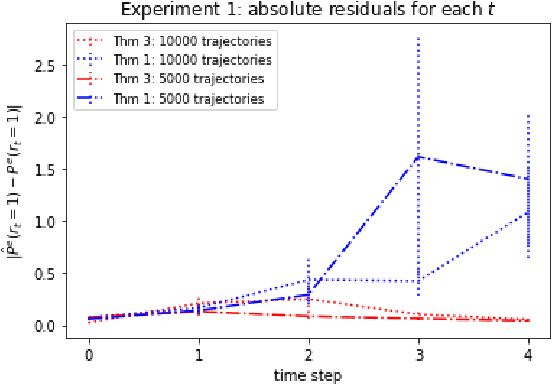
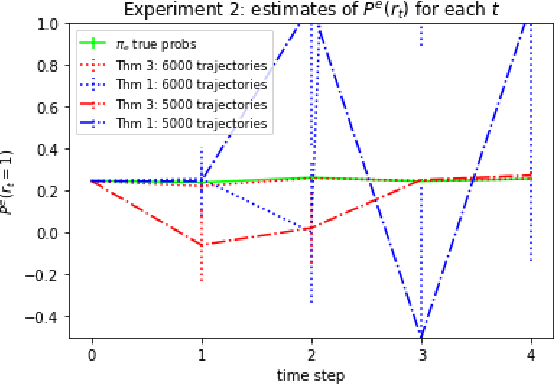
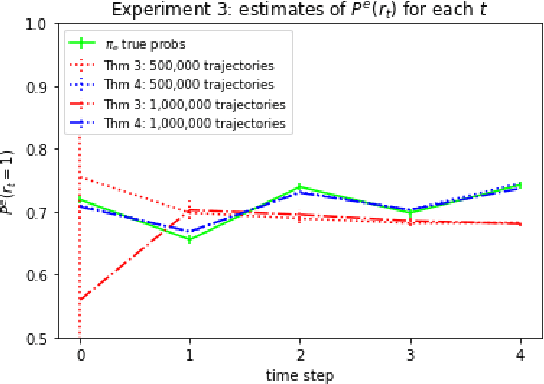
We consider off-policy evaluation (OPE) in Partially Observable Markov Decision Processes, where the evaluation policy depends only on observable variables but the behavior policy depends on latent states (Tennenholtz et al. (2020a)). Prior work on this problem uses a causal identification strategy based on one-step observable proxies of the hidden state, which relies on the invertibility of certain one-step moment matrices. In this work, we relax this requirement by using spectral methods and extending one-step proxies both into the past and future. We empirically compare our OPE methods to existing ones and demonstrate their improved prediction accuracy and greater generality. Lastly, we derive a separate Importance Sampling (IS) algorithm which relies on rank, distinctness, and positivity conditions, and not on the strict sufficiency conditions of observable trajectories with respect to the reward and hidden-state structure required by Tennenholtz et al. (2020a).