 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Effective Model-Based Variable Importance Measure
Paper and Code
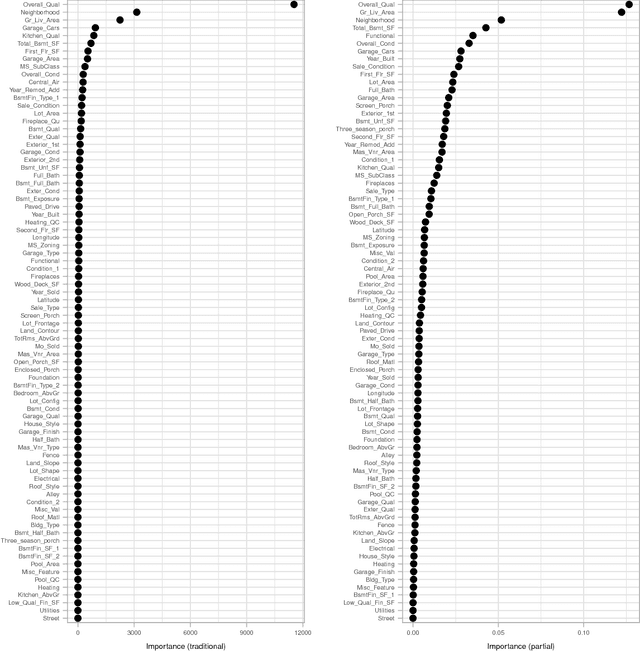

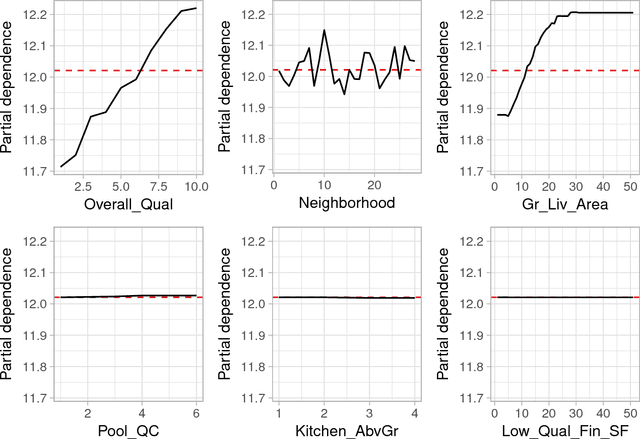
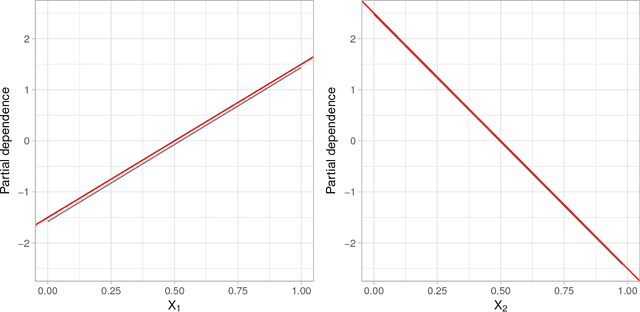
In the era of "big data", it is becoming more of a challenge to not only build state-of-the-art predictive models, but also gain an understanding of what's really going on in the data. For example, it is often of interest to know which, if any, of the predictors in a fitted model are relatively influential on the predicted outcome. Some modern algorithms---like random forests and gradient boosted decision trees---have a natural way of quantifying the importance or relative influence of each feature. Other algorithms---like naive Bayes classifiers and support vector machines---are not capable of doing so and model-free approaches are generally used to measure each predictor's importance. In this paper, we propose a standardized, model-based approach to measuring predictor importance across the growing spectrum of supervised learning algorithms. Our proposed method is illustrated through both simulated and real data examples. The R code to reproduce all of the figures in this paper is available in the supplementary materials.