 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA practical approach to evaluating the adversarial distance for machine learning classifiers
Paper and Code
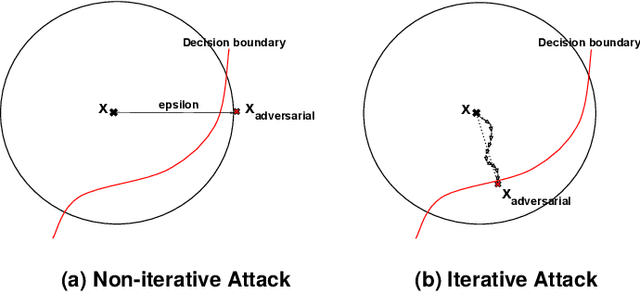
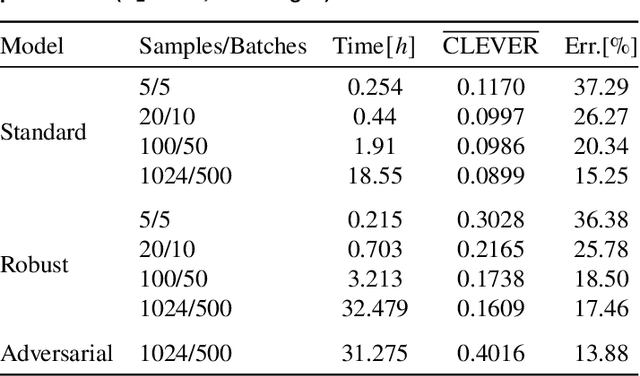
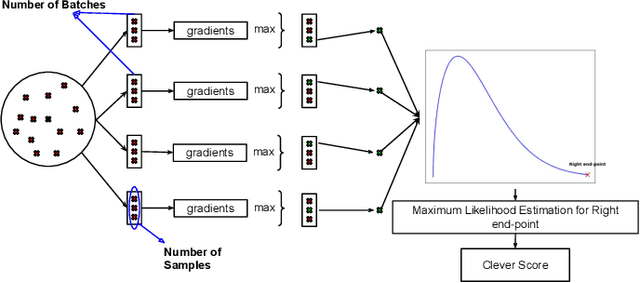
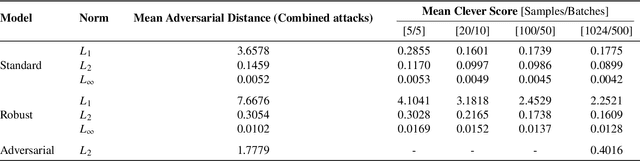
Robustness is critical for machine learning (ML) classifiers to ensure consistent performance in real-world applications where models may encounter corrupted or adversarial inputs. In particular, assessing the robustness of classifiers to adversarial inputs is essential to protect systems from vulnerabilities and thus ensure safety in use. However, methods to accurately compute adversarial robustness have been challenging for complex ML models and high-dimensional data. Furthermore, evaluations typically measure adversarial accuracy on specific attack budgets, limiting the informative value of the resulting metrics. This paper investigates the estimation of the more informative adversarial distance using iterative adversarial attacks and a certification approach. Combined, the methods provide a comprehensive evaluation of adversarial robustness by computing estimates for the upper and lower bounds of the adversarial distance. We present visualisations and ablation studies that provide insights into how this evaluation method should be applied and parameterised. We find that our adversarial attack approach is effective compared to related implementations, while the certification method falls short of expectations. The approach in this paper should encourage a more informative way of evaluating the adversarial robustness of ML classifiers.