 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Parallel Corpus of Theses and Dissertations Abstracts
Paper and Code
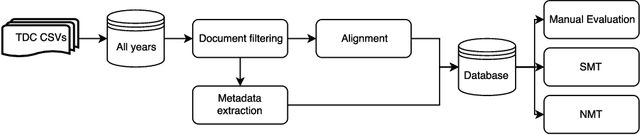
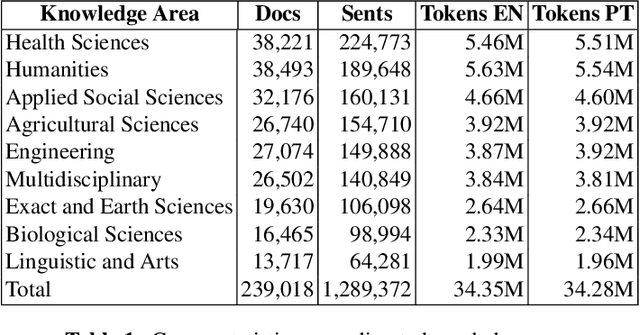

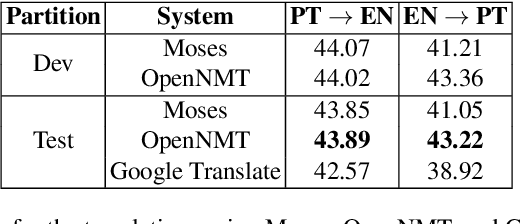
In Brazil, the governmental body responsible for overseeing and coordinating post-graduate programs, CAPES, keeps records of all theses and dissertations presented in the country. Information regarding such documents can be accessed online in the Theses and Dissertations Catalog (TDC), which contains abstracts in Portuguese and English, and additional metadata. Thus, this database can be a potential source of parallel corpora for the Portuguese and English languages. In this article, we present the development of a parallel corpus from TDC, which is made available by CAPES under the open data initiative. Approximately 240,000 documents were collected and aligned using the Hunalign tool. We demonstrate the capability of our developed corpus by training Statistical Machine Translation (SMT) and Neural Machine Translation (NMT) models for both language directions, followed by a comparison with Google Translate (GT). Both translation models presented better BLEU scores than GT, with NMT system being the most accurate one. Sentence alignment was also manually evaluated, presenting an average of 82.30% correctly aligned sentences. Our parallel corpus is freely available in TMX format, with complementary information regarding document metadata