 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Neuro-Symbolic ASP Pipeline for Visual Question Answering
Paper and Code


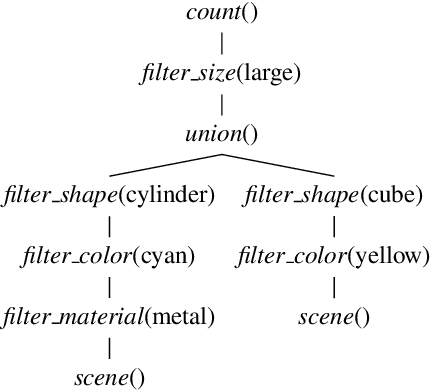
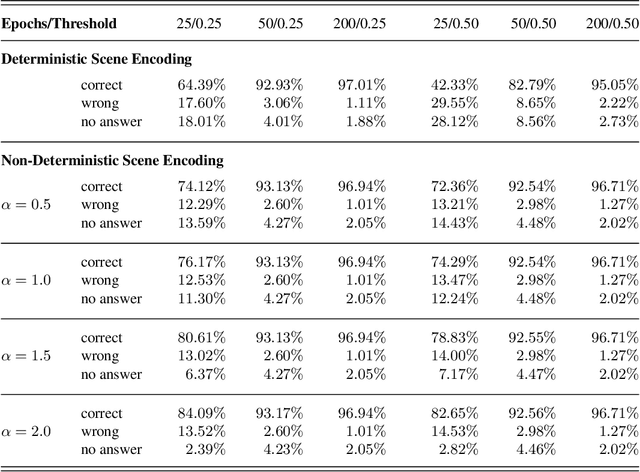
We present a neuro-symbolic visual question answering (VQA) pipeline for CLEVR, which is a well-known dataset that consists of pictures showing scenes with objects and questions related to them. Our pipeline covers (i) training neural networks for object classification and bounding-box prediction of the CLEVR scenes, (ii) statistical analysis on the distribution of prediction values of the neural networks to determine a threshold for high-confidence predictions, and (iii) a translation of CLEVR questions and network predictions that pass confidence thresholds into logic programs so that we can compute the answers using an ASP solver. By exploiting choice rules, we consider deterministic and non-deterministic scene encodings. Our experiments show that the non-deterministic scene encoding achieves good results even if the neural networks are trained rather poorly in comparison with the deterministic approach. This is important for building robust VQA systems if network predictions are less-than perfect. Furthermore, we show that restricting non-determinism to reasonable choices allows for more efficient implementations in comparison with related neuro-symbolic approaches without loosing much accuracy. This work is under consideration for acceptance in TPLP.