 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multimodal LSTM for Predicting Listener Empathic Responses Over Time
Paper and Code
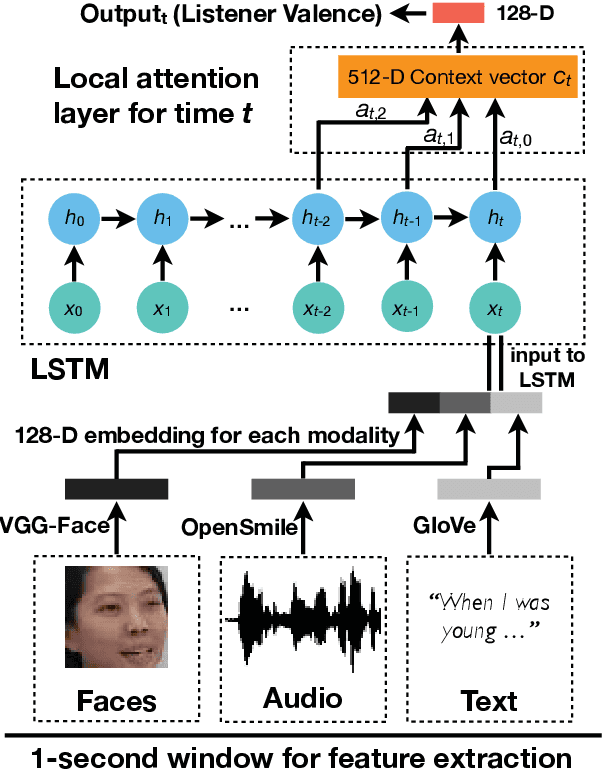
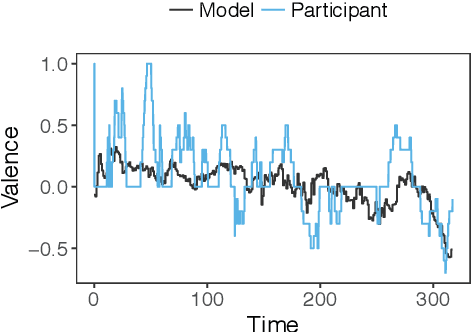
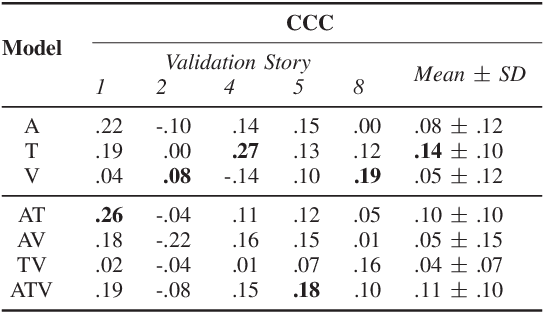
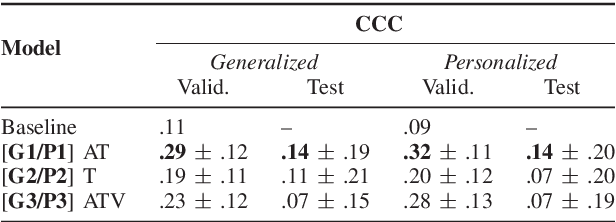
People naturally understand the emotions of-and often also empathize with-those around them. In this paper, we predict the emotional valence of an empathic listener over time as they listen to a speaker narrating a life story. We use the dataset provided by the OMG-Empathy Prediction Challenge, a workshop held in conjunction with IEEE FG 2019. We present a multimodal LSTM model with feature-level fusion and local attention that predicts empathic responses from audio, text, and visual features. Our best-performing model, which used only the audio and text features, achieved a concordance correlation coefficient (CCC) of 0.29 and 0.32 on the Validation set for the Generalized and Personalized track respectively, and achieved a CCC of 0.14 and 0.14 on the held-out Test set. We discuss the difficulties faced and the lessons learnt tackling this challenge.