 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Modeling Framework for Reliability of Erasure Codes in SSD Arrays
Paper and Code
Dec 23, 2021
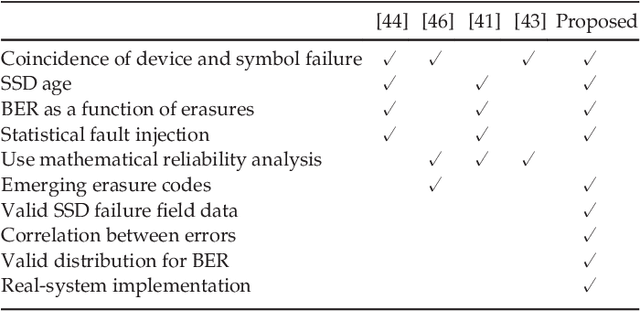
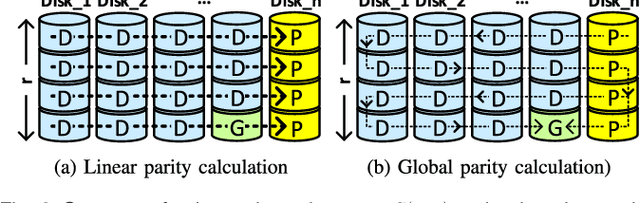

To help reliability of SSD arrays, Redundant Array of Independent Disks (RAID) are commonly employed. However, the conventional reliability models of HDD RAID cannot be applied to SSD arrays, as the nature of failures in SSDs are different from HDDs. Previous studies on the reliability of SSD arrays are based on the deprecated SSD failure data, and only focus on limited failure types, device failures, and page failures caused by the bit errors, while recent field studies have reported other failure types including bad blocks and bad chips, and a high correlation between failures. In this paper, we explore the reliability of SSD arrays using field storage traces and real-system implementation of conventional and emerging erasure codes. The reliability is evaluated by statistical fault injections that post-process the usage logs from the real-system implementation, while the fault/failure attributes are obtained from field data. As a case study, we examine conventional and emerging erasure codes in terms of both reliability and performance using Linux MD RAID and commercial SSDs. Our analysis shows that a) emerging erasure codes fail to replace RAID6 in terms of reliability, b) row-wise erasure codes are the most efficient choices for contemporary SSD devices, and c) previous models overestimate the SSD array reliability by up to six orders of magnitude, as they focus on the coincidence of bad pages and bad chips that roots the minority of Data Loss (DL) in SSD arrays. Our experiments show that the combination of bad chips with bad blocks is the major source of DL in RAID5 and emerging codes (contributing more than 54% and 90% of DL in RAID5 and emerging codes, respectively), while RAID6 remains robust under these failure combinations. Finally, the fault injection results show that SSD array reliability, as well as the failure breakdown is significantly correlated with SSD type.