 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Multi-f0 Modeling in SATB Choir Recordings
Paper and Code
Apr 10, 2019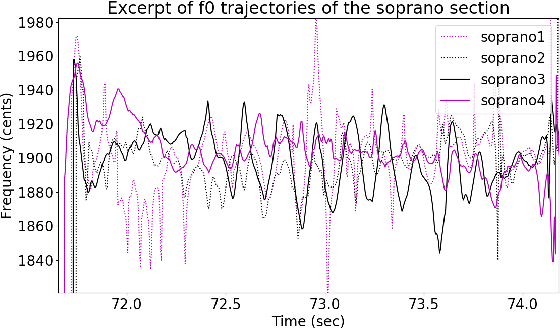
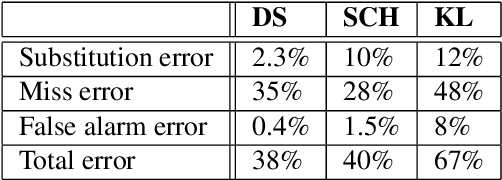
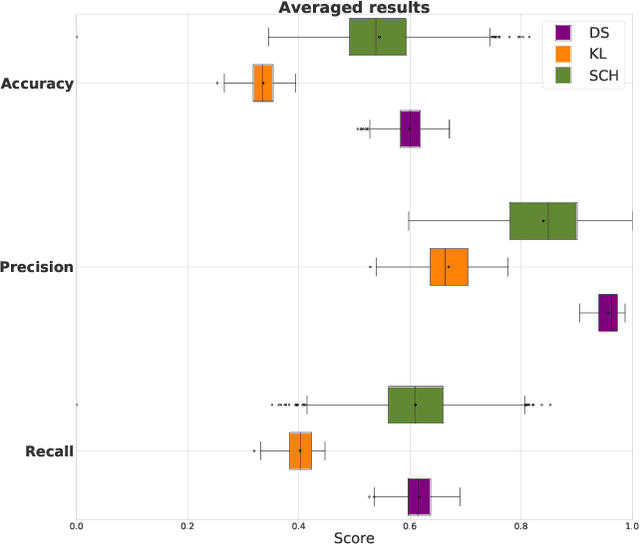
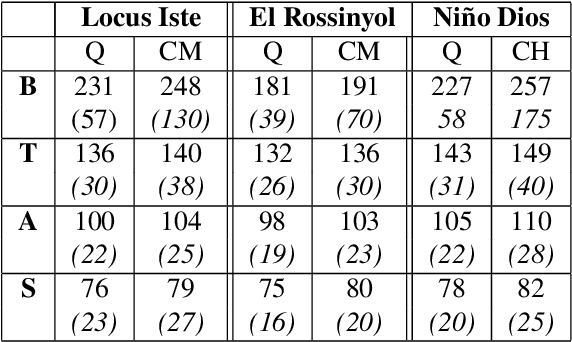
Fundamental frequency (f0) modeling is an important but relatively unexplored aspect of choir singing. Performance evaluation as well as auditory analysis of singing, whether individually or in a choir, often depend on extracting f0 contours for the singing voice. However, due to the large number of singers, singing at a similar frequency range, extracting the exact individual pitch contours from choir recordings is a challenging task. In this paper, we address this task and develop a methodology for modeling pitch contours of SATB choir recordings. A typical SATB choir consists of four parts, each covering a distinct range of pitches and often with multiple singers each. We first evaluate some state-of-the-art multi-f0 estimation systems for the particular case of choirs with a single singer per part, and observe that the pitch of individual singers can be estimated to a relatively high degree of accuracy. We observe, however, that the scenario of multiple singers for each choir part (i.e. unison singing) is far more challenging. In this work we propose a methodology based on combining a multi-f0 estimation methodology based on deep learning followed by a set of traditional DSP techniques to model f0 and its dispersion instead of a single f0 trajectory for each choir part. We present and discuss our observations and test our framework with different singer configurations.