 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Flexible Cell Classification for ML Projects in Jupyter Notebooks
Paper and Code

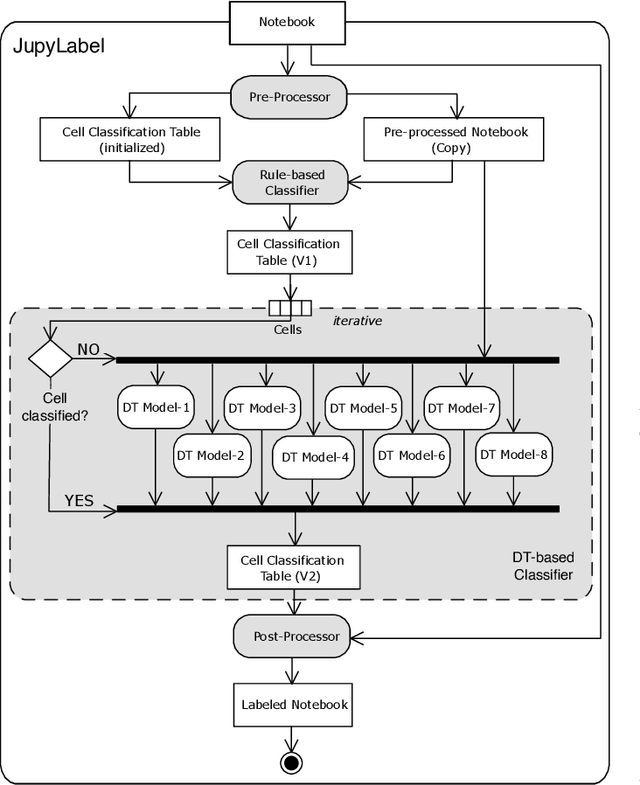
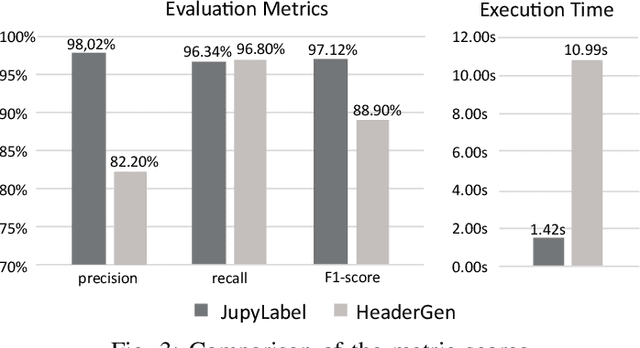
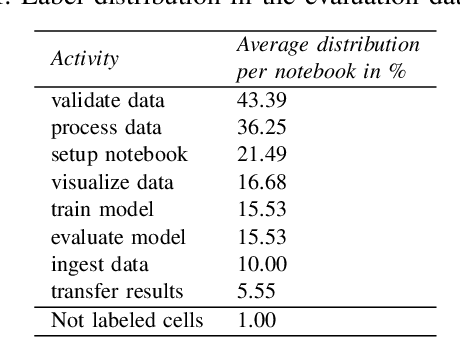
Jupyter Notebook is an interactive development environment commonly used for rapid experimentation of machine learning (ML) solutions. Describing the ML activities performed along code cells improves the readability and understanding of Notebooks. Manual annotation of code cells is time-consuming and error-prone. Therefore, tools have been developed that classify the cells of a notebook concerning the ML activity performed in them. However, the current tools are not flexible, as they work based on look-up tables that have been created, which map function calls of commonly used ML libraries to ML activities. These tables must be manually adjusted to account for new or changed libraries. This paper presents a more flexible approach to cell classification based on a hybrid classification approach that combines a rule-based and a decision tree classifier. We discuss the design rationales and describe the developed classifiers in detail. We implemented the new flexible cell classification approach in a tool called JupyLabel. Its evaluation and the obtained metric scores regarding precision, recall, and F1-score are discussed. Additionally, we compared JupyLabel with HeaderGen, an existing cell classification tool. We were able to show that the presented flexible cell classification approach outperforms this tool significantly.