 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA deep learning theory for neural networks grounded in physics
Paper and Code


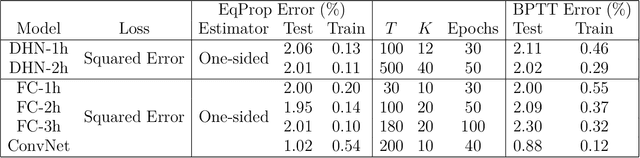
In the last decade, deep learning has become a major component of artificial intelligence, leading to a series of breakthroughs across a wide variety of domains. The workhorse of deep learning is the optimization of loss functions by stochastic gradient descent (SGD). Traditionally in deep learning, neural networks are differentiable mathematical functions, and the loss gradients required for SGD are computed with the backpropagation algorithm. However, the computer architectures on which these neural networks are implemented and trained suffer from speed and energy inefficiency issues, due to the separation of memory and processing in these architectures. To solve these problems, the field of neuromorphic computing aims at implementing neural networks on hardware architectures that merge memory and processing, just like brains do. In this thesis, we argue that building large, fast and efficient neural networks on neuromorphic architectures requires rethinking the algorithms to implement and train them. To this purpose, we present an alternative mathematical framework, also compatible with SGD, which offers the possibility to design neural networks in substrates that directly exploit the laws of physics. Our framework applies to a very broad class of models, namely systems whose state or dynamics are described by variational equations. The procedure to compute the loss gradients in such systems -- which in many practical situations requires solely locally available information for each trainable parameter -- is called equilibrium propagation (EqProp). Since many systems in physics and engineering can be described by variational principles, our framework has the potential to be applied to a broad variety of physical systems, whose applications extend to various fields of engineering, beyond neuromorphic computing.