 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Trainable Error Model for Sung Music Queries
Paper and Code
Jun 30, 2011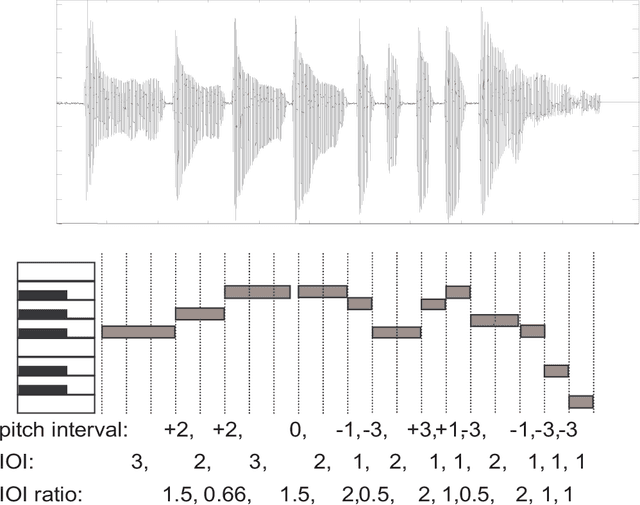
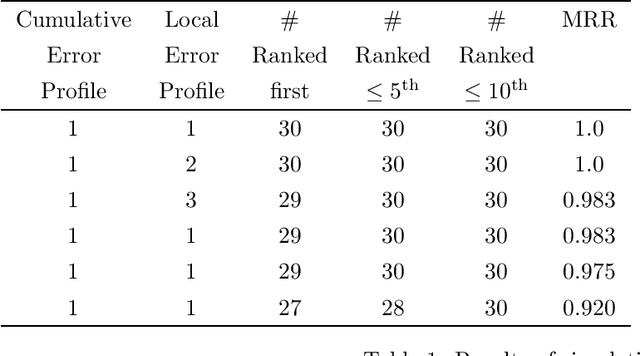
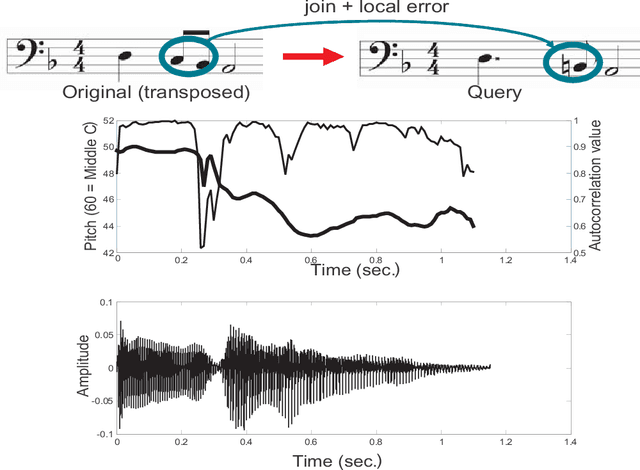
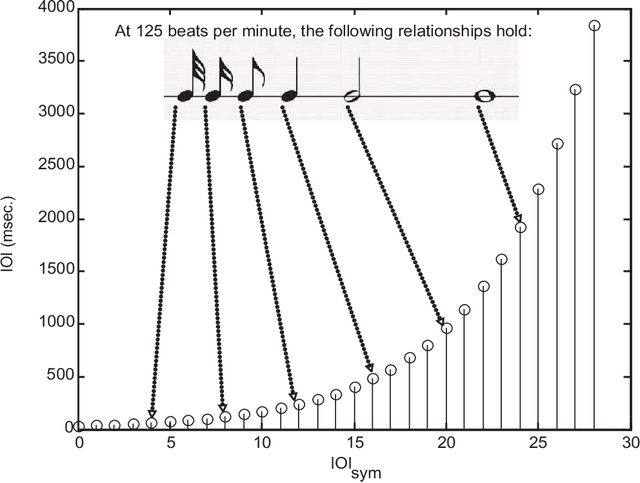
We propose a model for errors in sung queries, a variant of the hidden Markov model (HMM). This is a solution to the problem of identifying the degree of similarity between a (typically error-laden) sung query and a potential target in a database of musical works, an important problem in the field of music information retrieval. Similarity metrics are a critical component of query-by-humming (QBH) applications which search audio and multimedia databases for strong matches to oral queries. Our model comprehensively expresses the types of error or variation between target and query: cumulative and non-cumulative local errors, transposition, tempo and tempo changes, insertions, deletions and modulation. The model is not only expressive, but automatically trainable, or able to learn and generalize from query examples. We present results of simulations, designed to assess the discriminatory potential of the model, and tests with real sung queries, to demonstrate relevance to real-world applications.