 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Parametric Dynamic Mode Decomposition Algorithms for Thermal-Hydraulics Applications
Paper and Code


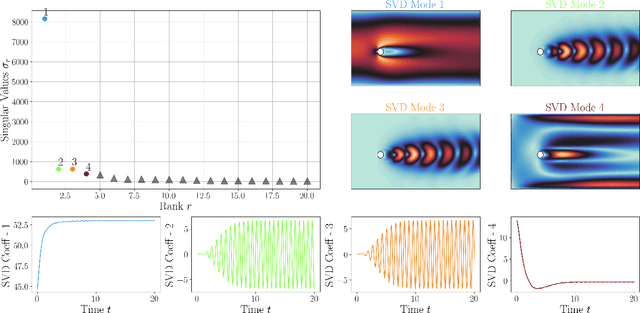

In recent years, algorithms aiming at learning models from available data have become quite popular due to two factors: 1) the significant developments in Artificial Intelligence techniques and 2) the availability of large amounts of data. Nevertheless, this topic has already been addressed by methodologies belonging to the Reduced Order Modelling framework, of which perhaps the most famous equation-free technique is Dynamic Mode Decomposition. This algorithm aims to learn the best linear model that represents the physical phenomena described by a time series dataset: its output is a best state operator of the underlying dynamical system that can be used, in principle, to advance the original dataset in time even beyond its span. However, in its standard formulation, this technique cannot deal with parametric time series, meaning that a different linear model has to be derived for each parameter realization. Research on this is ongoing, and some versions of a parametric Dynamic Mode Decomposition already exist. This work contributes to this research field by comparing the different algorithms presently deployed and assessing their advantages and shortcomings compared to each other. To this aim, three different thermal-hydraulics problems are considered: two benchmark 'flow over cylinder' test cases at diverse Reynolds numbers, whose datasets are, respectively, obtained with the FEniCS finite element solver and retrieved from the CFDbench dataset, and the DYNASTY experimental facility operating at Politecnico di Milano, which studies the natural circulation established by internally heated fluids for Generation IV nuclear applications, whose dataset was generated using the RELAP5 nodal solver.