 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Optimization Algorithms for Deep Learning
Paper and Code
Jul 28, 2020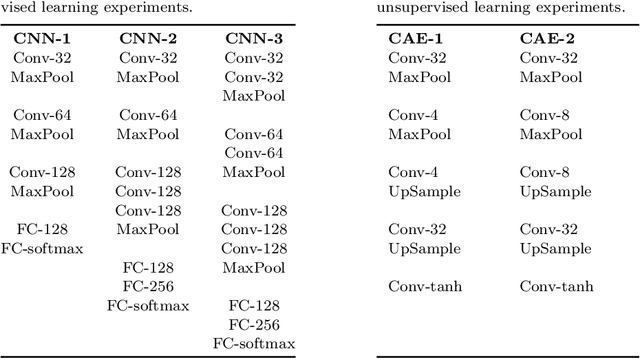
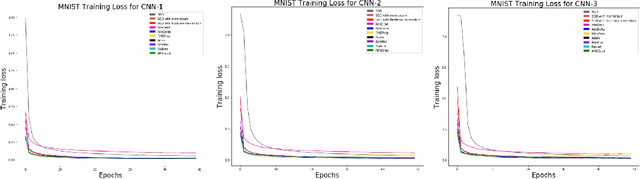
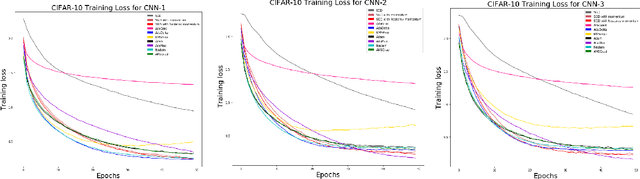
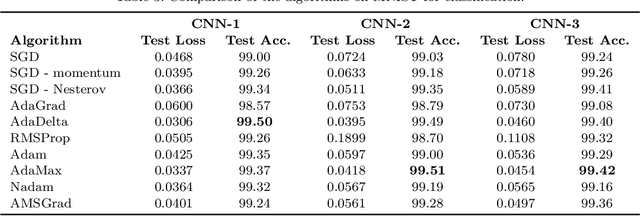
In recent years, we have witnessed the rise of deep learning. Deep neural networks have proved their success in many areas. However, the optimization of these networks has become more difficult as neural networks going deeper and datasets becoming bigger. Therefore, more advanced optimization algorithms have been proposed over the past years. In this study, widely used optimization algorithms for deep learning are examined in detail. To this end, these algorithms called adaptive gradient methods are implemented for both supervised and unsupervised tasks. The behaviour of the algorithms during training and results on four image datasets, namely, MNIST, CIFAR-10, Kaggle Flowers and Labeled Faces in the Wild are compared by pointing out their differences against basic optimization algorithms.