 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Batch Learning Framework for Scalable Personalized Ranking
Paper and Code
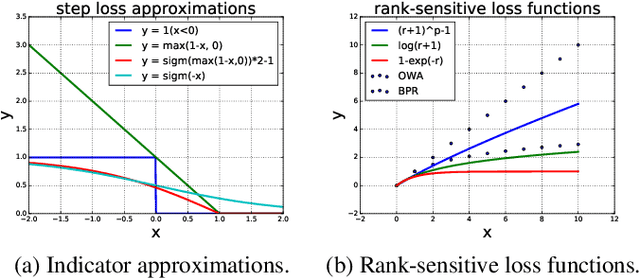

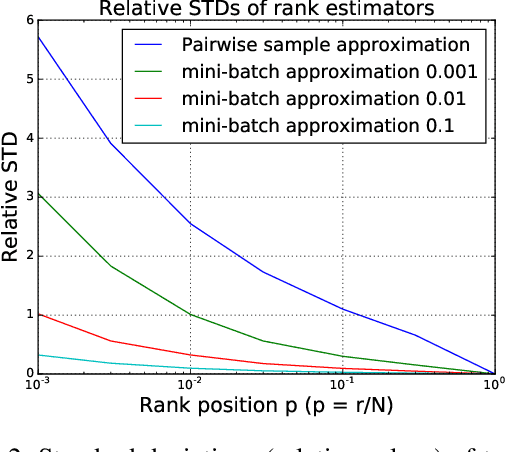

In designing personalized ranking algorithms, it is desirable to encourage a high precision at the top of the ranked list. Existing methods either seek a smooth convex surrogate for a non-smooth ranking metric or directly modify updating procedures to encourage top accuracy. In this work we point out that these methods do not scale well to a large-scale setting, and this is partly due to the inaccurate pointwise or pairwise rank estimation. We propose a new framework for personalized ranking. It uses batch-based rank estimators and smooth rank-sensitive loss functions. This new batch learning framework leads to more stable and accurate rank approximations compared to previous work. Moreover, it enables explicit use of parallel computation to speed up training. We conduct empirical evaluation on three item recommendation tasks. Our method shows consistent accuracy improvements over state-of-the-art methods. Additionally, we observe time efficiency advantages when data scale increases.